懒鸟飞:帝国cms模板专业分享平台,新域名:lanniaofei.com
最近张戈博客收录出现异常,原因并不明朗。我个人猜测存在如下几个直接原因:
对于前三个,已发生的已无法改变,要发生的也无法阻止。对于转载和采集,我也只能在Nginx加入UA黑名单和防盗链机制,略微阻碍一下了,但是实际起不到彻底禁止作用,毕竟整个天朝互联网大环境就是这样一个不好的风气,很多人都不愿意花时间、用心写文章,喜欢不劳而获的转载甚至是篡改抄袭。
对于第四点,真是忍无可忍。我很想对百度说,我忍你很久了。明明robots里面加入了禁止抓取这些动态地址和某些路径,但是蜘蛛依然每天抓取,而且还收录了!收录也没事,关键收录了动态地址居然不收录静态地址了??这是要闹咋样啊?
案例①:
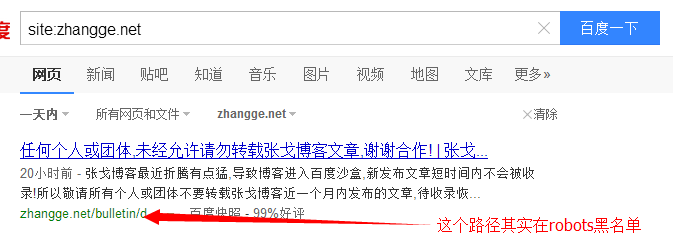
案例②:
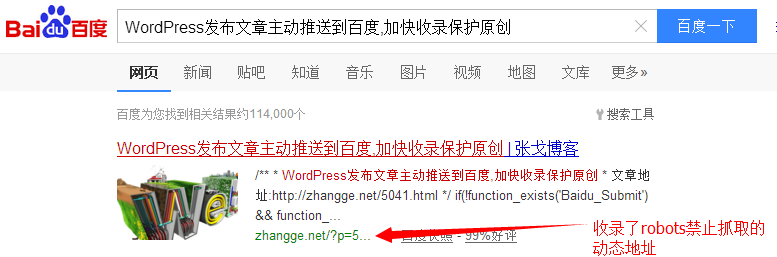
案例③: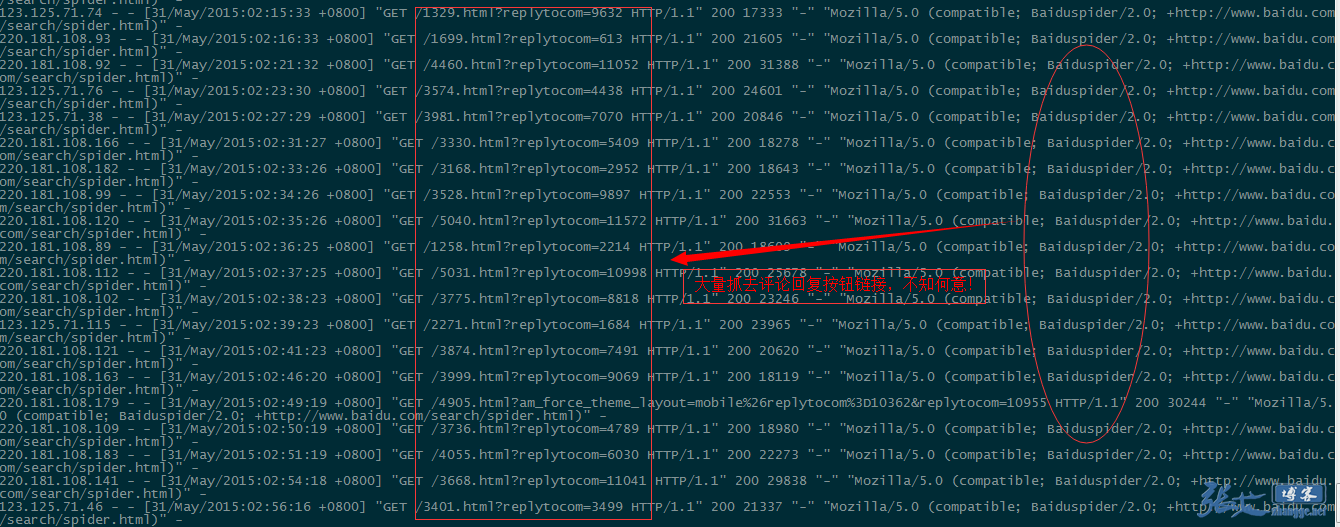
以上案例中的地址,我通过百度站长平台的robots检验结果都是被禁封的,真不知道百度怎么想的:
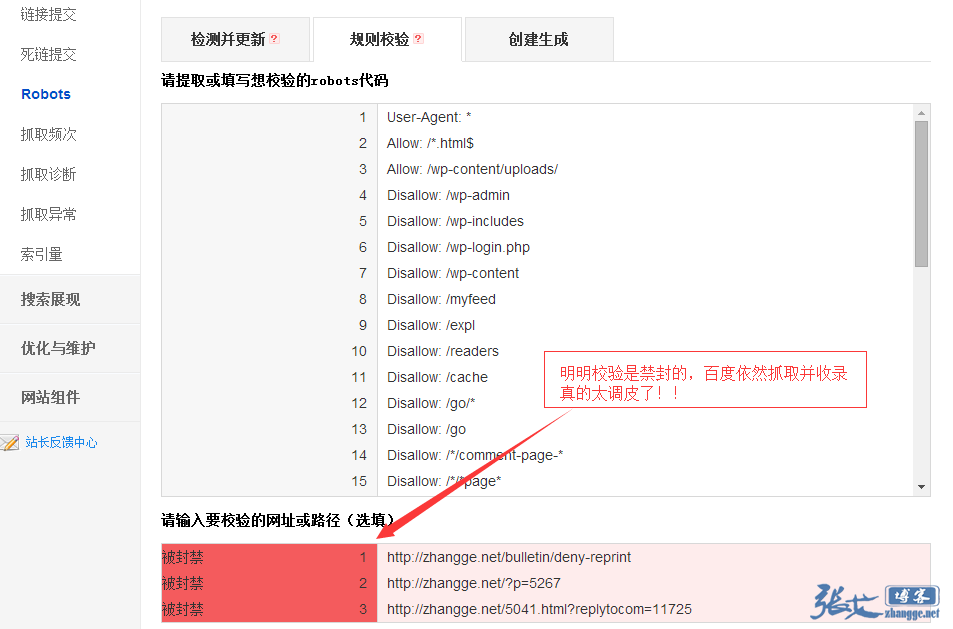
所以,我决定用极端手段,彻底禁止这些不听话的蜘蛛抓取那些我不想被收录的页面!robots协议显然还是太温柔了!下面看张戈怎么放大招吧!
张戈博客用的是 Nginx,所以直接在 server 中新增如下规则即可:
| ################################################# | |
| # 禁止蜘蛛抓取动态或指定页面规则 By 张戈博客 # | |
| # 原文地址:https://zhang.ge/5043.html # | |
| # 申 明:转载请尊重版权,保留出处,谢谢合作! # | |
| ################################################# | |
| server | |
| { | |
| listen 80; | |
| server_name zhang.ge; | |
| index index.html index.htm index.php default.html default.htm default.php; | |
| root /home/wwwroot/zhang.ge; | |
| #### 新增规则【开始】 #### | |
| #初始化变量为空 | |
| set $deny_spider ""; | |
| #如果请求地址中含有需要禁止抓取关键词时,将变量设置为y: | |
| if ($request_uri ~* "?replytocom=(d+)|?p=(d+)|/feed|/date|/wp-admin|comment-page-(d+)|/go") { | |
| set $deny_spider 'y'; | |
| } | |
| #如果抓取的UA中含有spider或bot时,继续为变量赋值(通过累加赋值间接实现nginx的多重条件判断) | |
| if ($http_user_agent ~* "spider|bot") { | |
| set $deny_spider "${deny_spider}es"; | |
| } | |
| #当满足以上2个条件时,则返回404,符合搜索引擎死链标准 | |
| if ($deny_spider = 'yes') { | |
| return 403; #如果是删除已收录的,则可以返回404 | |
| break; | |
| } | |
| #### 新增规则【结束】 #### | |
| #以下规则略... |
Ps:就是将上述代码中“新增规则【开始】”到“新增规则【结束】”内容添加到我们网站的 Nginx 配置-- server 模块 中的 root 指令之后即可。
Apache 测试了半天总是500错误,暂时先放弃了,有时间再来调整!
我自己测试写的规则如下,感兴趣的朋友可以自行测试看看,也许是我环境的问题。
| RewriteEngine On | |
| RewriteCond %{HTTP_USER_AGENT} (^$|spider|bot) [NC] | |
| RewriteCond %{REQUEST_URI} (/?replytocom=(d+)|?p=(d+)|/feed|/date|/wp-admin|wp-includes|/go|comment-page-(d+)) [NC] | |
| RewriteRule ^(.*)$ - [F] |
Ps:大概思路和Nginx一致,既匹配了蜘蛛UA,又匹配了禁止关键词的抓取,直接返回403(如何返回404,有知道的朋友请留言告知下,测试成功的朋友也敬请分享一下代码,我实在没时间折腾了。)
| /** | |
| * PHP比robots更彻底地禁止蜘蛛抓取指定路径代码 By 张戈博客 | |
| * 原文地址:https://zhang.ge/5043.html | |
| * 申 明:原创代码,转载请注保留出处,谢谢合作! | |
| * 使用说明:将一下代码添加到主题目录的functions.php当中即可。 | |
| */ | |
| ob_start("Deny_Spider_Advanced"); | |
| function Deny_Spider_Advanced() { | |
| $UA = $_SERVER['HTTP_USER_AGENT']; | |
| $Request_uri = $_SERVER['PHP_SELF'].'?'.$_SERVER['QUERY_STRING']; | |
| $Spider_UA = '/(spider|bot|)/i'; //定义需要禁止的蜘蛛UA,一般是spider和bot | |
| //禁止蜘蛛抓取的路径,可以参考自己的robots内容,每个关键词用分隔符隔开,需注意特殊字符的转义 | |
| $Deny_path = '/?replytocom=(d+)|?p=(d+)|/feed|/date|/wp-admin|wp-includes|/go|comment-page-(d+)/i'; | |
| //如果检测到UA为空,可能是采集行为 | |
| if(!$UA) { | |
| header("Content-type: text/html; charset=utf-8"); | |
| wp_die('请勿采集本站,因为采集的站长木有小JJ!'); | |
| } else { | |
| //如果发现是蜘蛛,并且抓取路径匹配到了禁止抓取关键词则返回404 | |
| if(preg_match_all($Spider_UA,$UA) && preg_match_all($Deny_path,$Request_uri)) { | |
| //header('HTTP/1.1 404 Not Found'); | |
| //header("status: 404 Not Found"); | |
| header('HTTP/1.1 403 Forbidden'); //可选择返回404或者403(有朋友说内链404对SEO不太友好) | |
| header("status: 403 Forbidden"); | |
| } | |
| } | |
| } |
使用很简单,将上述PHP代码添加到主题目录下放 functions.php 当中即可。
测试效果很简单,直接利用百度站长平台的抓取诊断工具即可:
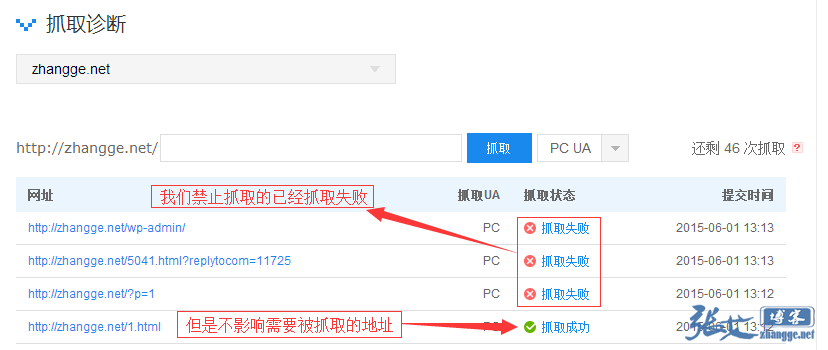
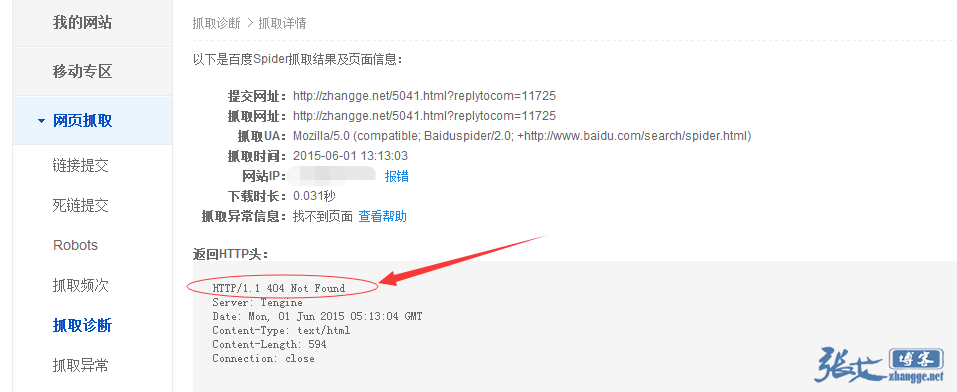
点开看看可以发现真的是返回404:
最后,结合张戈博客之前分享的《SEO技巧:Shell脚本自动提交网站404死链到搜索引擎》即可将这些无用的收录全部删除:
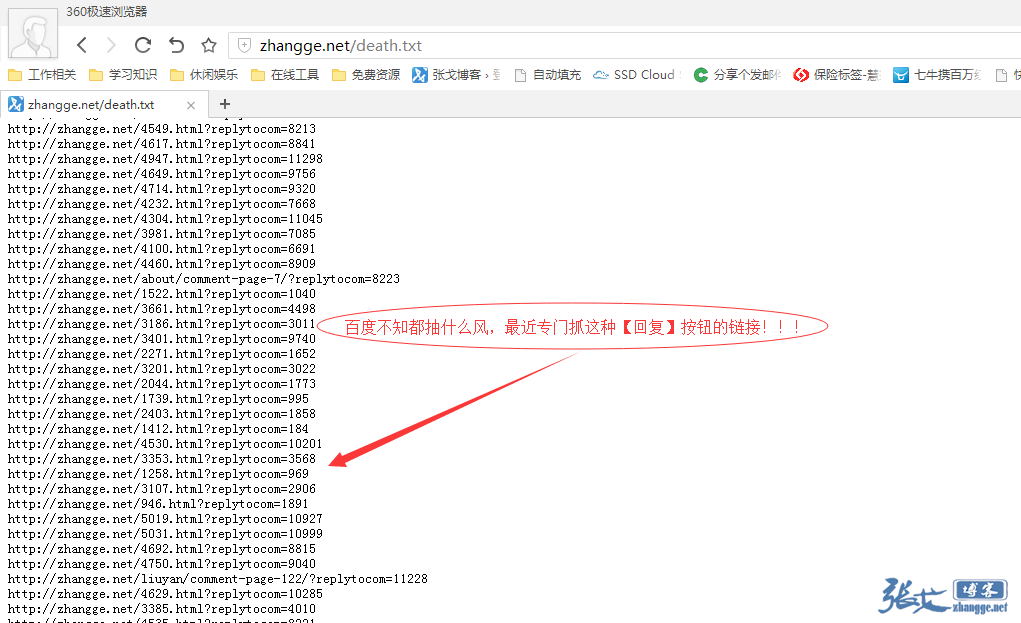
有朋友说我这个是黑帽手法,用户可以访问,而搜索引擎却404,很适合淘宝客网站的商品外链。是什么手法我不清楚,我只知道实用就好!特别是张戈博客那些外链,都是用/go?url=这个路径来跳转的,现在这样处理后,就算搜索引擎不遵循robots硬是要抓取,就只能抓到404了!
好了,本文就分享到这,这种做法和张戈博客之前分享的《SEO分享:彻底禁止搜索引擎收录非首选域名的方法》一样,属于极端优化做法,实施后,我们的索引肯定会大量下降,因为很多垃圾索引或收录都将被删除,但是这是良性的做法,因为优质且不重复的内容才是提高排名的王道!
 淘宝店
淘宝店





